Transformer・BERTを用いたSNSログからなりすまし検知の学習
1. 背景
警視庁の「令和元年におけるサイバー空間をめぐる脅威の情勢等について」[1]によると、2019年のサイバー犯罪件数は9,519件と過去5年間で17.9%増加している。また、警察庁の2019年9月の全国の15歳以上の男女1万人を対象に実施したアンケート調査の結果によると、「過去1年間にサイバー犯罪の被害に遭う恐れのある経験をした」と解答した人は28.9%、「過去1年間にサイバー犯罪の被害に遭った」と解答した人は13.7%に達した。この中でもSNSのなりすまし被害は多く、友人のTwitterが乗っ取られたり、私もInstagramを乗っ取られたことがあったりと、非常に身近な犯罪の一つである。この対策として乗っ取られにくいパスワードの設定や怪しい安全認証メールに返信しない等がなされているが、被害件数は増える一方である。このなりすまし被害を防止するために、なんらかの自然言語処理的・機械学習的アプローチができないだろうか。
SNSのログは作者特定によく用いられる小説の文書に比べて短文であることや、短文であるため複数文から意味を成すことが多い。そのため、SNSのログから作者特定を行うためには文脈を理解した埋め込み表現の獲得を行えるようなモデルを利用したいと考えた。
そこで今回は、2017年12月に発表された論文「Attention Is All You Need」[2]で提案されたTransformerを用いたBERTを利用する。BERTはMasked Language ModelingとNext Sentence Predictionと呼ばれる事前学習を行うことで、単語の埋め込み表現に1文中・全文章中における意味を与えることができるモデルである。また、ルールベースの識別器に比べ入力と出力の相関関係が複雑であることもBERTの優れた点である。
2. 目的
BERTと自分のLINEログを用いたなりすまし検知を行い、その利用可能性について考察する。
3. 手法
3.1 事前学習済みモデル及びJUMAN
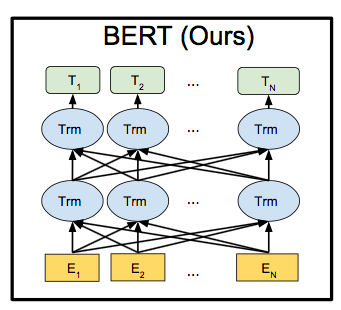
Transformer・BERTのすべてを解説するとあまりに長くなってしまうため、要点だけ解説する。 TransformerはRNNやCNNを使わずAttentionのみを使用したEncoder-Decoderモデルで、Encoder,DecoderそれぞれにはMulti-Head Attention層とPosition-wise全結合層を使用している。
3.2.1 Multi-Head Attention層
自然言語処理における多くのAttentionモデルでは各単語がそれぞれQ,K,Vの3つのベクトルを持っており、QとKによってAttentionスコアを、そのAttemtonスコアとVの加重和が各単語の潜在表現となる。Transformerではこの先述した計算をheadの数分行い、それをConcatした配列と重みW0で掛け算することでその層の潜在表現とするMulti-Head Attentionを行っている。headを複数個用意することでそれぞれが異なる情報を取得することができ、より複雑な表現をもった分散表現を獲得することができる。式は以下の通りとなっている。
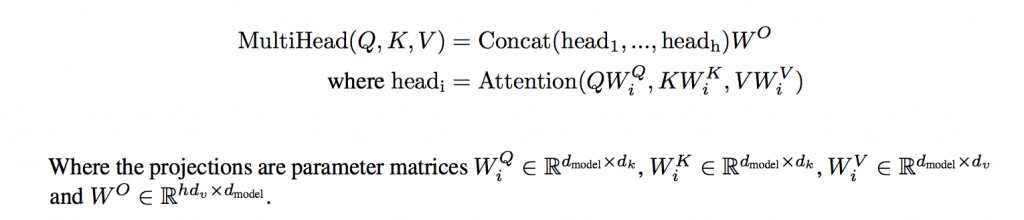
3.2.2 Position-wise全結合層
Attention層の後にはPosition-wise全結合層が入っている。Position-wise層では、単語ごとに独立してNN計算を行う層である。ただし、重みは共有されており、式は以下の通りとなっている。
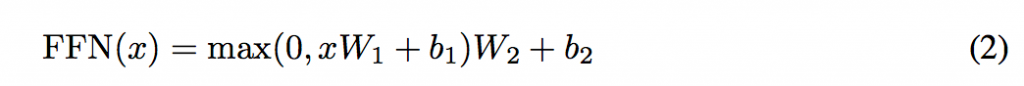
3.2.3 BERTについて
BERTはTransformerを用いて単語埋め込み列を生成するモデルである。BERTの事前学習はMasked Language ModelingとNext Sentence Predictionによって行われており、これによって文章内における単語の解釈や両方向の文同士の繋がりを単語の埋め込み表現に与えることができる。詳しくは論文[3]を見ていただきたい。
4 テストと結果4.1 データセット
今回は自分及び友人20人の過去約5年間のLINEのトークログ(約45000件)を用意し、trainデータ40000件とtestデータ5000件をランダムに選び適切なデータクレンジングを行った。
4.2 テスト
BERTのSingle Sentence Cassification TasksモデルのCLSに人物のタグ(自分なら0,自分でないなら1)を、E1以降に文章を入力する。クラスの判定はClass Labelの位置に該当する出力ベクトルの先頭の値によって行う。
4.3結果
10分程度の学習を5回行い、その正答率の平均は83.54%であった。
5. 考察と今後の研究5.1 BERTによるなりすまし検知の有用性について
前述した識別器を使い、一文ではなく複数文の識別を行えば実際のなりすまし検知プログラムとして利用可能なレベルだと考えられる。ファインチューニングに利用したSNSのログデータは1年程度そのSNSを利用していれば用意可能なデータ数であり、また複数のSNSからログを取得することでより集めやすくなる。
5.2 データクレンジングの重要性
一般の自然言語処理では全角・半角の統一や数字の除去といったデータクレンジングが行われるが、それだけを行っても今回の学習は収束しない、もしくは4割程度の精度の識別器ができてしまった。その後、着信通知やスタンプ等のLINEに特有の不必要なデータを削除すると著しく収束が早くなったためデータクレンジングは非常に重要な要素であることが分かった。5-1のように複数のSNSのログを使う場合は、そのSNSに合ったデータクレンジングが必要になる。
5.3 より高度な識別のために
より高精度な識別器を作るためには、以下のような改善が必要だと考えられる
・今回は特定のユーザーのみを学習したが、スパムメール識別器のように実際に乗っ取られた際に送られてきたメッセージを集め学習する[4]
・LINE等のSNSに特化した辞書の追加や、事前学習に用いる文章の選定を行う。
・BERTではなくSentence-BERTを使うことで、より高精度の文章全体からの埋め込み表現(今回でいえば作者ラベル)を得られる可能性がある。