人のイントネーションを真似するシステム
[背景と目的]
人間の社会的相互作用の特徴のひとつとして無意識的な模倣がある。人は無意識に他者のしぐさや癖、振る舞いを模倣し、また模倣された人は模倣した人に対して良い印象や好感度を持つことが知られている。これをカメレオン効果と呼ぶ[1]。この効果を利用して、ビジネスや恋愛における相手に好印象を与える手法として模倣が提案されている。既存研究においても、カメレオン効果を利用したユーザが話しやすいエージェントの検討が行われており、模倣動作によってユーザの話しやすさが向上したと報告されている[2]。そこで本研究は、話者A, B それぞれの音声を録音し、音声の特徴量を操作することで話者Aのイントネーションを話者Bのイントネーションに真似るシステムを開発する。
[手法]
- まず、イントネーションを変換させたい話者Aの音声を3秒間で入力し、基本周波数、スペクトル包絡、非周期性指標を推定
- 次に、話者Bも同様に音声を入力する
- 話者Aの基本周波数を話者Bの基本周波数に変換する。その際、話者Aのその他の特徴量はそのまま
[結果]
1. 「こんにちは」と入力した結果
話者A「こ→ん→に→ち→は→」
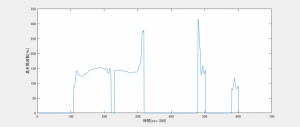
図1. 話者Aの基本周波数(こんにちは)
話者B「こ↑ ん→に→ち→は→」
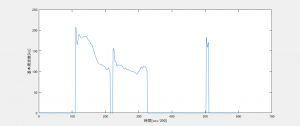
図2. 話者Bの基本周波数(こんにちは)
合成音声「こ↑ ん→に→ち→は→」
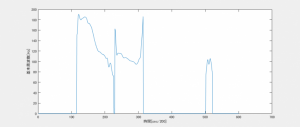
図3. 合成音声の基本周波数(こんにちは)
2. 「トマト」と入力した結果
話者A「ト↑ マ→ト→」
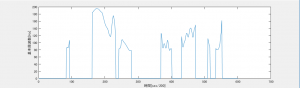
図4. 話者Aの基本周波数(トマト)
話者B「ト→マ↑ ト→」
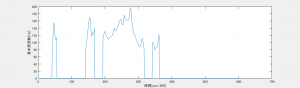
図5. 話者Bの基本周波数(トマト)
合成音声「ト↓ マ↓ ト→」
![]()
図6. 合成音声の基本周波数(トマト)
[考察]
話者Aと話者Bの発話において、一字一句それぞれの発音タイミングが合うと、狙い通りに音声合成ができた。
時間的な都合のため話者Aと話者Bは同一人物であったため、合成音声に話者Bの声質が影響するかどうかを調べることができなかった。
一語一句の発音のタイミングがずれると、合成された音声は全く聞き取れないものとなった。
根本的な解決にはならないが、入力された音声データの発話までの無音時間を削除し発話のタイミングをそろえることができれば、発音のタイミングのズレを多少解消できると思ったが、うまく実装できず時間切れになってしまった。
今後の課題としては音声を音素ごとに区切るセグメンテーション処理の実装を行い、実際にロボットの会話機能に実装する。
[感想]
卒業研究配属後の2か月間で、研究テーマを自分で考えることから始め、発表までする本プロジェクトで多くのことが学ぶことができた。
もともとプログラミングに対して苦手意識があるので、そこを含めてより計画的に研究を進めていきたいと思った。