word2vecと多層パーセプトロンを使用した文章から印象の推定
1. はじめに
インターネットショッピングサイトを利用する人にとって、カスタマーレビューは非常に重要である。 他の購入者の実際の感想は客の購買欲を高めるだけでなく、商品をよく吟味して買いたいという層にとっても貴重な判断材料といえる。それらカスタマーレビューには大きく2つの項目が用意されていることが多い。1つはレビューの本文となる具体的な感想を記す部分。そしてもう1つは、商品やサービス全体を点数で評価する部分である。大手インターネットショッピングサイトAmazonでは、レビュー記入者は本文のほかに5点満点の点数をつけることができるようになっており、それらは5つの星という形で表現されている。
しかしながら、カスタマーレビュー本文とこの評点の間にはいかなる相関があるのかはよくわかっていない。つまり、評価を言葉として表した場合と全体の印象を数値や視覚的な記号として表した場合とで、本来は等しくあるべき評価が変わってしまっている可能性が考えられる。
本プロジェクトはカスタマーレビュー本文と評点から、「言葉」と「印象」の関係性の探索を目指す。今回は機械学習的手法を用いて、本文と評点の学習から関係性の探索を行った。
2. 背景
カスタマーレビューの一例を挙げる(図1)。このレビューの本文から記入者がどのような判断指標に基づき、星3という評点をつけたのかは推測することは難しい。また、レビューワー以外の人がこのレビュー本文を読んだ際に同じく星3という評点を下すとも限らない。

図1. カスタマーレビューの例
3. 手法
3.1 word2vec
word2vecとは 分散表現によって単語を200次元ほどの空間に圧縮する方法である。特徴として、単語にベクトルの性質を当てはめられるということがある。一例としては、意味的に近い単語同士の距離が小さくなったり、和や差を定義できたりすることが知られている。 今回はレビューの本文を形態素解析によって単語に分割したのち、助詞を除くすべての単語をword2vecによってベクトル化した。そして、文章に含まれるそれら単語ベクトルのベクトル和をとることで文章を表現するベクトルを生成した(図2)。

図2. 文章ベクトルの生成例
3.2 多層パーセプトロン
入力200ノード、隠れ層200ノード、出力5ノードの2層パーセプトロンで逆誤差伝播法を採用したシステムを作成した。学習データはword2vecによって生成した文章ベクトル48968件、教師信号はそれらの評点とした。学習回数は20回、学習効率は0.01で学習を行い、トレーニング用のデータから50件のテストデータをランダムに選び評価を行った。
4. テストと結果
テストデータをトレーニング用のデータからランダムに50件選び出して入力し、システムの出力する推定値と真値の比較を行った。出力時関数は最も推定値の大きい評点を1とするような関数を使用したため、ラベルと一致したかどうかを正答率として評価を行った。 結果として5回のテストの正答率の平均は62%であった。
次に学習の効果が出ているのかを判断するため、確率分布に従った推測によって期待される正答率を計算した(表1)。これによって、確率分布に従った推定では49%ほどの正答率しか期待できないことが分かり、学習の効果はあったことが結果として得られた。
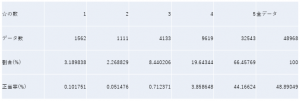
表1. 星の数の分布と確率的正答率
5. 品詞間の優位性の考察
言葉から印象を推定するにあたって、文章中でどのような働きをする語がより印象を表すといえるのかを考察した。今回は文中での単語の働きの区分として「品詞」に着目した。 テストデータに含まれる名詞、形容詞、動詞、助動詞、副詞の全5品詞から注目品詞を一つ取り除き、正答率の差から品詞間の重要度の違いを明確化したところ表2のような結果が得られた。
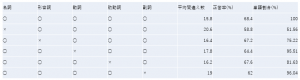
表2. 品詞と正答率の関係の関係
結果から、 印象を表すにあたって品詞には重要性の違いがあることが分かった。名詞や副詞は単語数の割合に対して正答率への影響が大きいことから、よく印象を表す語であると考えられる。以上より、wor2vecによってつくった単語ベクトルの大きさを品詞に応じて変化させることで、より正答率を上げることが示唆された。
6. 文章の長さと正答率の考察
文章の長さが正答率に影響を与えている可能性を考察した。文章の長短によって相対的に重要な単語の割合に対する不要な単語の割合が大きくなるではないかと考え、文章中の単語の数と正答率の関係を調査した。結果を図3に示す。
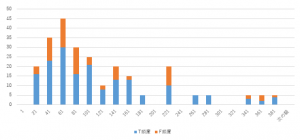
図3. 単語数と正答率の関係
図3からは、「文章が長いと間違いが多い」「少ないと間違いが多い」といった定性的な事実は言えななかった。逆に言えば文の長さと正答率には関係が認められないので、文章の長さを考慮した学習は行う必要がないとも考えられる。
7. まとめ
word2vecと多層パーセプトロンを使って「言葉」から「印象」の推定を行った。結果として、以下を得ることができた。
・文章を学習して「言葉」から「印象」を推定することは可能である
・「印象」をよく表す品詞が存在する
・文の長さと推定の正答率には関係がない
以上の結果から「言葉」として表現したものから数値化した「印象」を推定することができ、精度を上げる可能性も示唆された。一方、課題として推定の精度自体はあまりよくなく、学習データ量にかなり依存するということが挙げられる。また今後の展望として、ロボットとのコミュニケーションにおいて、ロボットが自分から発信する言葉の面白さや適合度を自己推定することなどに応用が期待できるといえるのではないだろうか。今後は人とロボットとのコミュニケーションという文脈で研究を進めていきたい。
8. おわりに
最後まで読んでくださった方、本当にありがとうございます。
今回このFTMPで、自分でテーマを決めるところから最終発表まで2か月間でやるというのは自分にとってかなり刺激的であり、打ち込めるプロジェクトでした。機械学習や自然言語処理といったものは知識としてはあるが、手を動かしたことはなかったという自分だったので、実際にプログラムを書いたりデータをとったりする過程はメチャクチャ勉強になりました。この経験は研究生活のスタートダッシュとしてだけではなく、内容的にも今後の研究に大いに役立つと感じました。